
















AI-AIoT
深度學習這檔事絕對不是運算效能夠大就能搞定
人工智慧是一個相當巨大的學術領域,現在主流探討的層級,由上而下依序是:人工智慧→機器學習→人工神經網路→深度學習(深度的人工神經網路)→卷積神經網路。

深度學習:處理龐大且複雜的資料
深度學習的兩個階段和三個層次
人工智慧晶片有幾種?
一窩蜂人工智慧晶片前你需要知道GPGPU的幾件事
人工智慧伺服器並不是只有插滿GPU就好

深度神經網路(Deep Neural Network, DNN)的發展
提高AI學習效率以促進AI產業化到產業AI化

歡迎來到科技巨頭掌握眾人資料並深入企業IT的世界
開源方案不等於萬靈丹
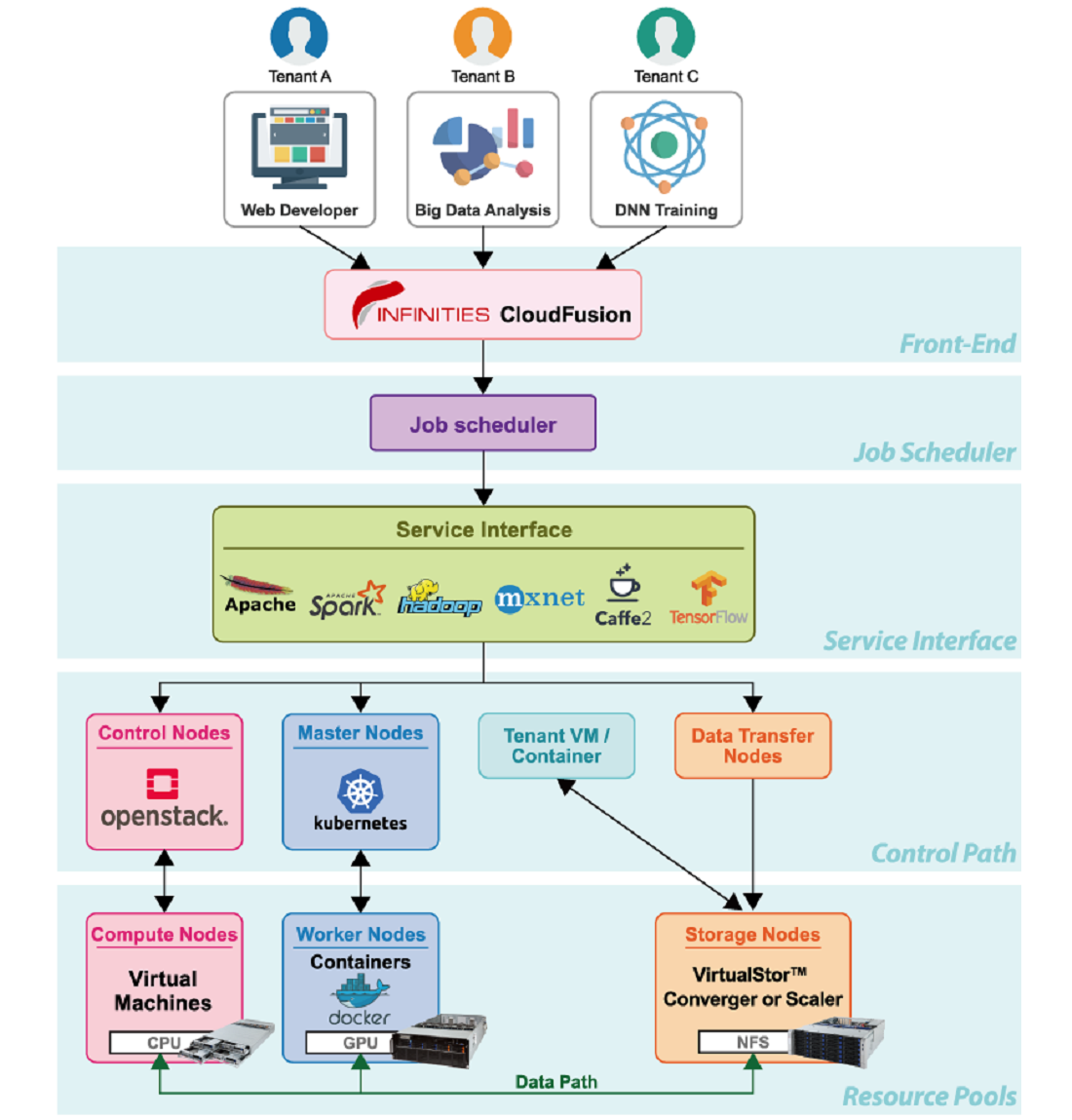
將AI、雲端、容器與軟體定義儲存融為一體

高效能運算
AI & AIoT
機器學習
人工智慧
深度學習
圖形處理器
軟體定義網路
WE RECOMMEND



RELATED ARTICLES

AI & AIoT
如何將人工智慧導入醫療保健業
從事醫療與健康產業的讀者,請花幾分鐘閱讀本篇文章,了解人工智慧(AI)為這個領域所帶來的嶄新商機,並認識能助您從中受益的AI工具。本篇是技嘉科技「Power of AI」系列文章,目的是介紹不同產業的最新AI趨勢,鼓勵前瞻者把握AI浪潮,找尋自己的機會。

Tech Guide
如何挑選您的AI伺服器?(上)CPU和GPU
生成式人工智慧和其他AI工具盛行的當下,挑選合適的AI伺服器成為各產業的首要任務。技嘉科技最新發表《科技指南》,帶領讀者認識AI伺服器的八個關鍵零組件,本篇從最重要的元件開始,即中央處理器(CPU)和圖形處理器(GPU)。挑選適當的運算晶片,打造量身訂做的人工智慧超算平台,可以讓工作事半功倍,為使用者開創全新的巔峰。

AI & AIoT
帶您快速跟上人工智慧AI趨勢的十大問答
大家都在談人工智慧(AI),您是否也希望擁有基本的知識,參與這個話題的討論?別擔心,技嘉科技為您準備了介紹AI趨勢的十大問答,讓您能快速理解人工智慧的概念!

AI & AIoT
如何將人工智慧導入汽車和運輸產業
若您從事汽車與運輸業,請花幾分鐘閱讀本篇文章,了解人工智慧(AI)所開拓的嶄新機會,認識能助您拓展更多可能性與商機的科技工具。本篇是技嘉科技「Power of AI」系列文章,目的是介紹不同產業的AI趨勢,協助具有先見之明的前瞻者利用AI創造自己的機會。
想要掌握最新科技動向?馬上訂閱!
訂閱電子報