

Productivity at Scale for the AI Factory Era: Servers × Liquid Cooling × G-REX
Generative AI, large language models (LLMs), and high-performance computing (HPC) are reshaping modern data centers into AI factories. As rack power density reaches 100 kW and beyond, scaling compute is no longer just a performance challenge, it is an energy, cooling, and operational challenge.
According to a 2024 report from the U.S. Department of Energy (DOE) and Lawrence Berkeley National Laboratory (LBNL), data center power demand will continue to grow rapidly, placing sustained pressure on electrical and cooling infrastructure. To scale AI sustainably, cooling must be designed as a first-class system, not an afterthought.
Direct Liquid Cooling: Designed In, Not Bolted On
Unlike retrofit liquid cooling kits for air-cooled servers, GIGABYTE Direct Liquid Cooling (DLC) servers are engineered for liquid cooling from day one. High-heat components are coupled directly to the liquid loop through cold plates, enabling the majority of system heat to be removed at the source. Compared to air cooling, which relies on high airflow and energy-intensive room cooling, DLC shortens the thermal path, improves efficiency, and significantly reduces cooling overhead. Independent studies and field evaluations confirm that cold-plate DLC is a mature technology. DLC has demonstrated stable operation under 140 kW rack-level IT loads, making it suitable for large-scale AI and HPC deployments.

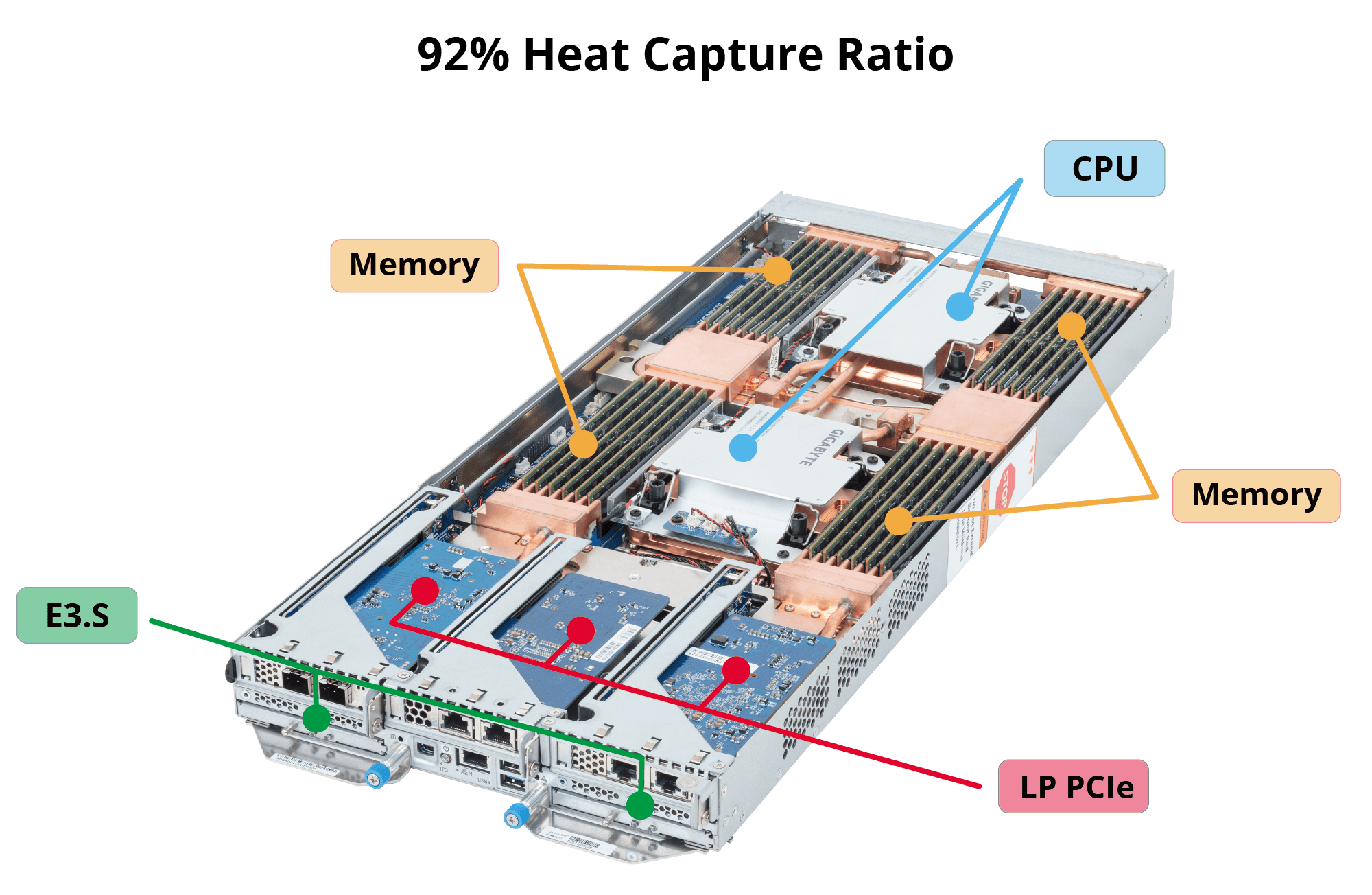
>92% Heat Capture Ratio: Built for High-Density AI and GPU Clusters
Heat Capture Ratio (HCR) is a key indicator of liquid cooling effectiveness. GIGABYTE DLC servers remove over 92% of total system heat directly through liquid cooling, leaving minimal residual heat to be handled by air.
Operational benefits include:
- Reduced or eliminated internal server fans
- Lower data center cooling and chiller demand
- Improved PUE and overall energy efficiency
- Increased stability for sustained AI training and high-power GPU workloads
GIGAPOD: Modular, Scalable AI Infrastructure
In production environments, the real challenge is not deploying a single high-performance GPU server, it is operating hundreds of racks consistently and reliably. GIGAPOD extends GIGABYTE’s DLC technology into a fully integrated, liquid-cooled compute rack solution. Servers, networking, power, and cooling are pre-integrated and validated at the factory, enabling predictable performance and faster time to deployment.
| Name | Positioning | Application | Details | Features |
|---|---|---|---|---|
| GIGAPOD AI | High‑performance GPU architecture built for AI training and inference | Large‑scale AI training, generative AI inference, LLM training clusters | HGX / OAM/ PCIe accelerator cards | Extreme AI performance, optimized thermal efficiency, turnkey deployment |
| GIGAPOD HPC | Scalable compute architecture optimized for HPC and cloud workloads | Scientific simulation, engineering analysis, cloud computing, national labs / university HPC | CPU‑based clusters with multi‑node configurations | High stability and efficiency, modular deployment, support for MRDIMM and high‑speed networking |

Key Advantages:
- Shared cooling architecture across multiple racks
- Linear scalability aligned with compute density
- Centralized management for AI factory operations
- Support for rapid deployment (L11 / L12 delivery models)
GIGAPOD is designed as a standardized building block for enterprise AI factories, cloud service providers, and research institutions, reducing integration complexity and accelerating expansion.
Learn More: GIGAPOD Solution
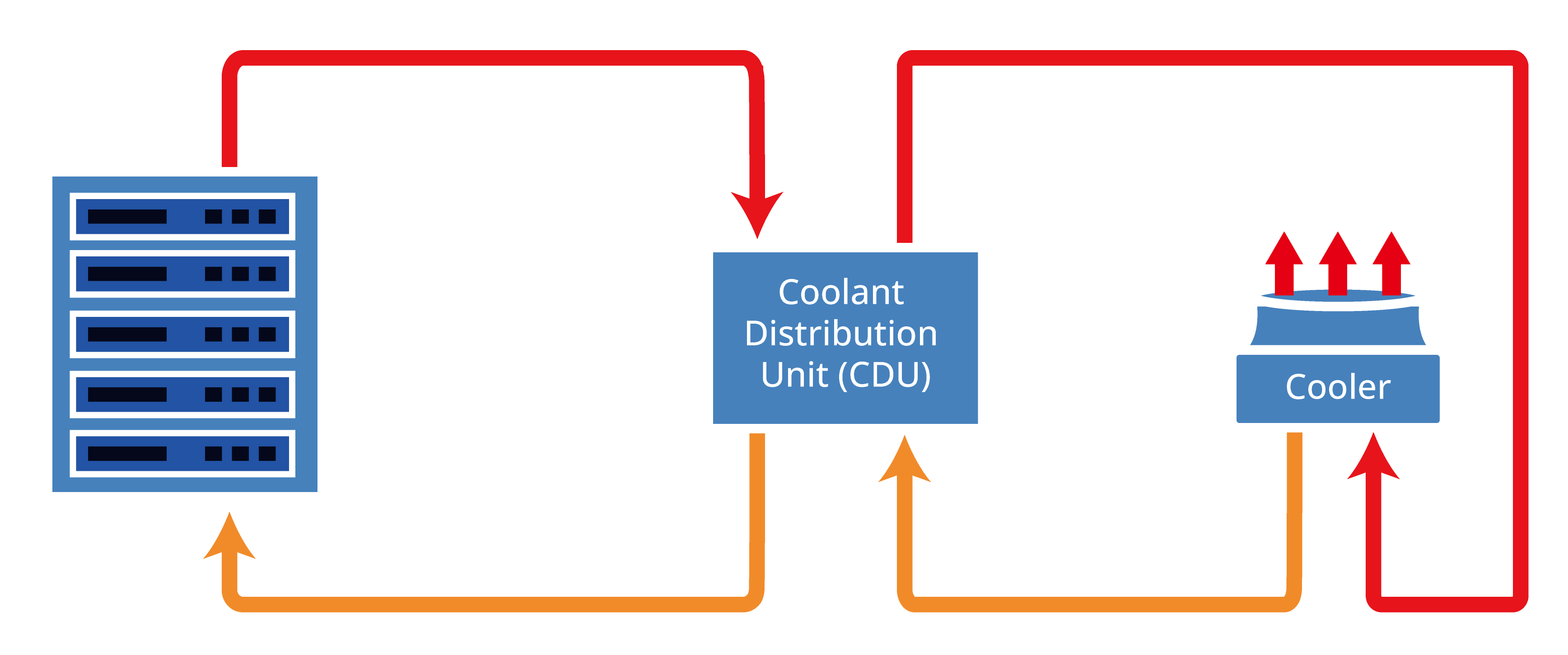
Warm Water Cooling up to 45°C, Reducing Chiller Dependency and Energy Cost
Energy efficiency at scale often comes from minimizing chiller usage. Industry studies show liquid cooling systems operating at near-ambient or elevated supply temperatures can reduce chiller runtime and extend free cooling availability.
GIGAPOD is engineered to support stable operation with inlet water temperatures up to 45°C, allowing compute capacity to scale without proportional increases in energy usage.
This aligns with modern data center best practices: lower water temperature does not equal higher efficiency, system-level optimization does.
G-REX: Unified Operations for OT and IT Infrastructure
Liquid-cooled data centers introduce a growing number of operational technology (OT) systems, including CDUs, rear-door heat exchangers (RDHx), and environmental controls. Without integration, these systems create operational complexity. G-REX is GIGABYTE’s middleware platform and a core component of GIGABYTE POD Manager (GPM). It consolidates cooling and power infrastructure data and presents it through IT-friendly, cluster-level interfaces.
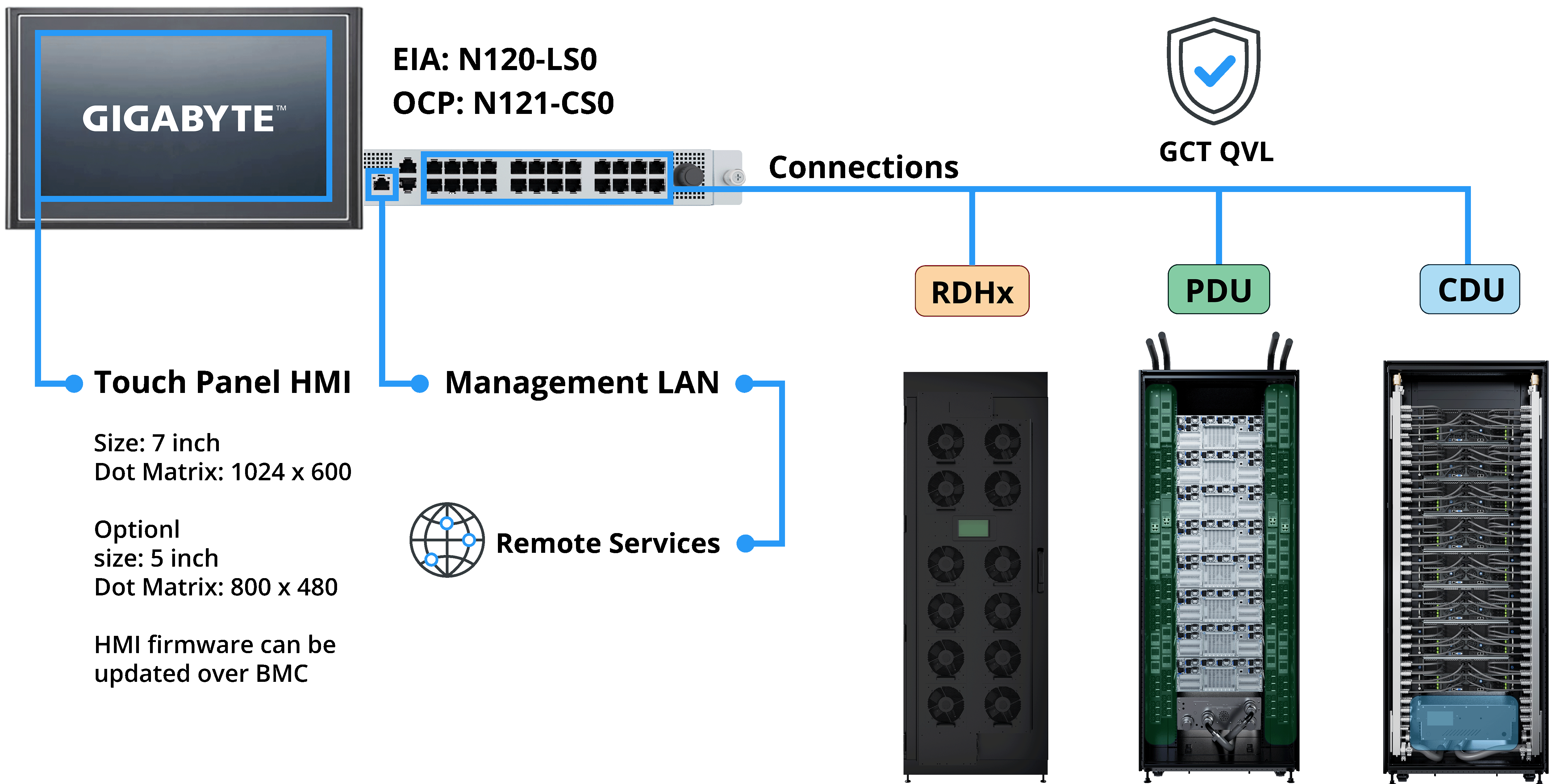
Cluster-Level Visibility and Control
- Real-time monitoring across racks and subsystems
- Unified view of cooling, power, and environmental data
- Seamless integration with higher-level cluster management platforms
Open Standards and APIs
G-REX supports Modbus, Redfish, and REST APIs, enabling integration with in-rack, in-row, sidecar CDUs, and rear-door heat exchangers. Customers can adopt liquid cooling incrementally without locking into a single vendor ecosystem.
Built for Enterprise Productivity: A Complete Path from Deployment to Operations
In the AI era, infrastructure is a strategic productivity asset. Enterprises require solutions that are scalable, energy efficient, and operationally predictable. By combining DLC servers, GIGAPOD rack-scale systems, and G-REX cluster operations, GIGABYTE delivers a fully integrated AI infrastructure platform, from deployment to long-term operations. The result is lower total cost of ownership, faster time to value, and sustainable AI scalability, the foundation enterprises need to operate AI factories with confidence.

Liquid-Cooled GIGAPOD Configurations
GIGAPOD AIGIGAPOD HPC
| GPU Solutions | Supported Systems | Systems per Rack | Rack Height | Racks per Scalable Unit (Compute + Management) | Power Consumption per Rack | PDU per Rack | CDU |
|---|---|---|---|---|---|---|---|
| NVIDIA GB300 NVL72 | DLB2-CB3 | 18 | 48U | 16+8 | 140kW | 6 x 63A | In-Rack |
| In-Row | |||||||
| NVIDIA GB200 NVL72 | DLA2-CB0 | 18 | 48U | 16+10 | 130kW | 6 x 63A | In-Rack |
| In-Row | |||||||
| NVIDIA HGX B300 | G4L4-SD3-LAX7 G4L4-ZD3-LAX7 | 8 | 42U | 9+4 | 109kW | 6 x 63A 2 x 125A | In-Rack |
| 9+3 | In-Row | ||||||
| TO46-SD3-LA07 | 44OU | 9+4 | 90kW | 6 x 63A | In-Rack | ||
| 9+3 | In-Row | ||||||
| AMD Instinct MI355X | G4L3-ZX1-LAT4 | 8 | 48U | 4+1 | 120kW | 4 x 100A | In-Rack |
| In-Row | |||||||
| NVIDIA HGX B200 | 8 | 42U | 4+1 | 103kW | 4 x 100A | In-Rack | |
| In-Row | |||||||
| AMD Instinct MI325X | G4L3-ZX1-LAX2 | 8 | 48U | 4+1 | 110kW | 4 x 100A | In-Rack |
| In-Row | |||||||
| NVIDIA HGX H200 | G593-SD1-LAX3 G593-ZD1-LAX3 | 8 | 48U | 4+1 | 85kW | 4 x 63A | In-Rack |
| In-Row | |||||||
| G4L3-SD1-LAX3 G4L3-ZD1-LAX3 | 42U | 80kW | In-Rack | ||||
| In-Row | |||||||
| AMD Instinct MI300X | G593-SX1-LAX1 G593-ZX1-LAX1 | 8 | 48U | 4+1 | 85kW | 4 x 63A | In-Rack |
| In-Row | |||||||
| G4L3-ZX1-LAX1 | 90kW | 4 x 100A | In-Rack | ||||
| In-Row |
Resources

Topic
Advanced Data Center Cooling Solutions for AI & Supercomputing


GIGABYTE Direct Liquid Cooling
Watch Video

GIGABYTE Direct Liquid Cooling Solution
Watch Video

Article
GIGABYTE Deep Dive: How We Built Our Industry-leading Liquid Cooling Solution

Article
How to Get Your Data Center Ready for AI? Part One: Advanced Cooling


Direct Liquid Cooling in 60 seconds
Watch Video

Your data center keeps heating up? Go Direct Liquid Cooling!
Watch Video

From Air to Liquid & Immersion Cooling - A Perfect Fit for Your Data Center
Watch Video