PCIe 架構OAM 模組

| 規格 | 詳細內容 |
|---|---|
| 尺寸外型 | 雙插槽 PCIe CEM |
| GPU 架構 | AMD CDNA™ 4 |
| GPU 運算單元 | 128 |
| INT8 / INT8 (Sparsity) | 支援 (w/ sparsity 2:4) |
| FP8 | 支援 (w/ sparsity 2:4) |
| FP16, BF16 | 支援 (w/ sparsity 2:4) |
| MXFP4 | 支援 |
| FP64 | 支援 |
| 專用記憶體容量 | 144 GB HBM3E |
| 記憶體頻寬 | 4.0 TB/s |
| 匯流排介面 | PCIe Gen5 x16 |
| 散熱方式 | 被動式散熱 |
| 電源接頭 | 16-pin 12VHPWR |
| TBP | 600W (可設定為450W) |
| 虛擬化支援 | 支援最多 4 個分區 |

AMD Instinct™ MI300 系列
概覽詳細規格

百萬兆次運算時代的加速核心
- 專為最嚴苛工作負載打造的 AMD Instinct™ MI325X GPU,具備 256GB 記憶體與每秒 6 TB 頻寬,結合卓越效能與高能源效率,並支援矩陣稀疏運算(Matrix Sparsity),以最佳化 AI 訓練與推論效能。
- 全球首款資料中心級整合加速處理單元(APU),AMD Instinct™ MI300A,突破 CPU 與 GPU 之間的效能瓶頸,消除程式設計負擔並簡化資料管理流程。
- 由 AMD EPYC™ 處理器與 AMD Instinct™ GPU 與 APU 驅動的全球最快超級電腦 El Capitan 與 Frontier,不僅在 TOP500 榜單名列前茅,同時於 GREEN500 榜上展現傑出的能源效率,充分展現 AMD 在高效能運算與 AI 加速領域的領導地位。
- 技嘉科技為百萬兆次運算時代推出先進伺服器方案,將 AMD Instinct™ MI325X 與 MI300X GPU 以開放加速模組(OAM)型式安裝於通用基板(UBB),搭載於 GIGABYTE G 系列伺服器中。整合 CPU 與 GPU 的 AMD Instinct™ MI300A APU 則配置於 GIGABYTE G383 系列,支援四組 LGA 插槽設計。此系列系統兼具高運算密度、卓越擴充性與冷卻效率,協助企業與研究機構推進 AI 與 HPC 的創新發展。
以 AMD ROCm™ 7.0 開創新世代極致效能
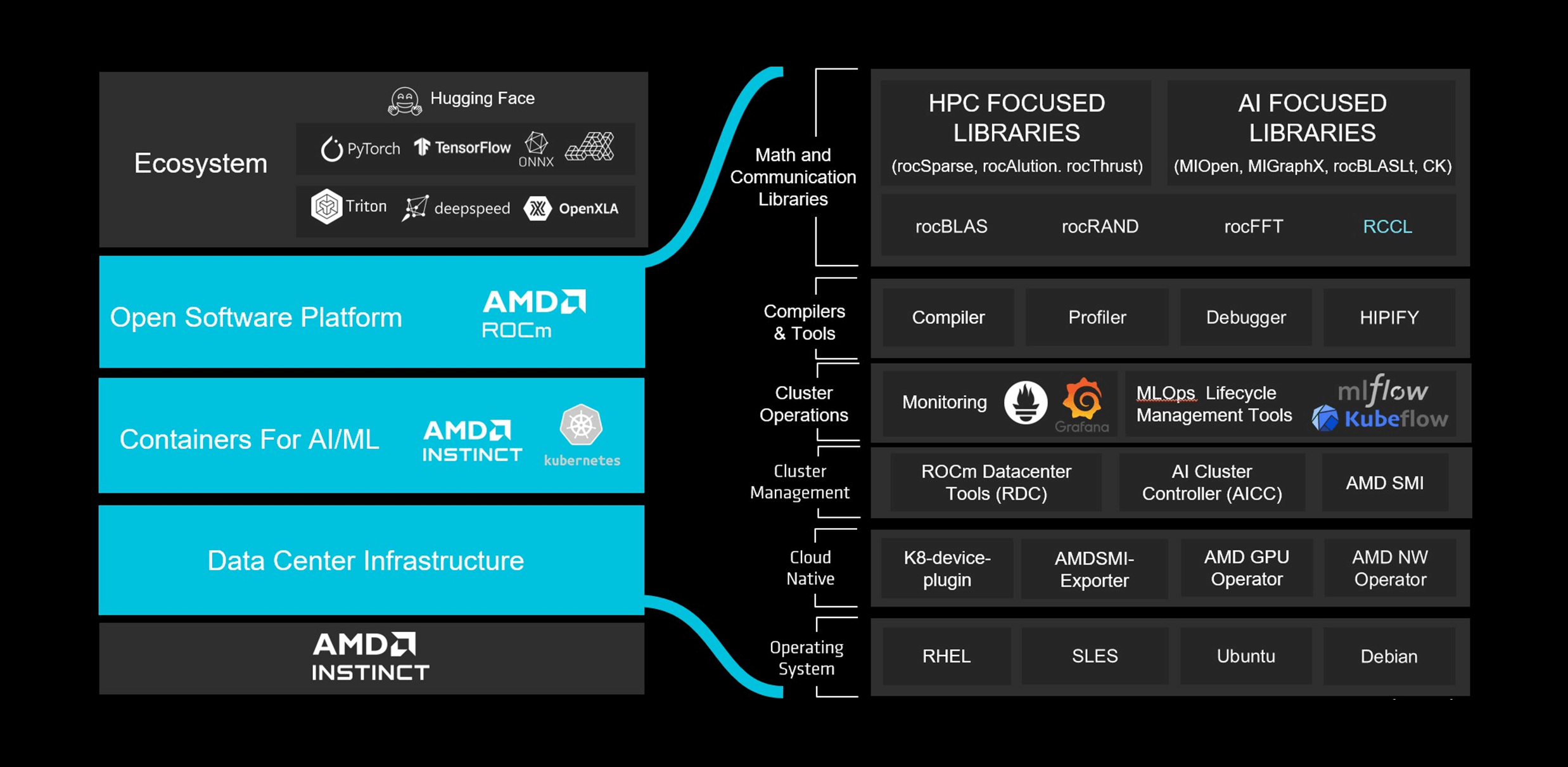
AMD ROCm™ 7.0 軟體堆疊是讓 AMD Instinct™ MI350 系列發揮極致效能的關鍵差異化技術。開發者能在幾乎不需修改程式碼的情況下,進行高效能 AI 與 HPC 應用開發。MI350 系列 GPU 已針對主流框架如 PyTorch、TensorFlow、JAX、ONNX Runtime、Triton、vLLM 進行全面最佳化,並透過自動核心生成與持續驗證,提供零時差的模型支援。
|
|
.[1] (MI300-080)AMD 於 2025 年 5 月 15 日進行測試,測量 ROCm 6.x(搭配 vLLM 0.3.3)與 ROCm 7.0 預覽版(搭配 vLLM 0.8.5)在推論效能上的差異。測試環境採用 8 組 AMD Instinct MI300X GPU,運行 Llama 3.1-70B(TP2)、Qwen 72B(TP2)及 Deepseek-R1(FP16)等模型,批次大小介於 1 至 256 、序列長度為 128 至 204 。所述效能提升以三個 LLM 模型的平均每秒字元處理數(Tokens Per Second, TPS)計算。實際結果可能因系統設定與工作負載而異。
選擇搭載 GIGABYTE AMD Instinct™ 伺服器平台

高密度運算
伺服器以高密度運算為設計核心。UBB GPU 支援氣冷式 8U 及液冷式 4U 伺服器,PCIe CEM 則支援 2U 及 4U 伺服器。

高效能運算
透過客製化伺服器設計,確保頂級 CPU 與 GPU 穩定發揮峰值效能,提供最高水準的運算結果。

橫向擴展
伺服器配備多組擴充插槽,可安裝乙太網路或 InfiniBand 網路介面卡(NIC),實現各節點間的高速通訊。

先進散熱
隨著導入直接液冷(DLC)技術,改善系統整體表現,處理器與 GPU 的熱設計功耗(TDP)持續增長也不構成問題,充分發揮尖端運算的最大潛能。

能源效率
透過即時電源管理、自動風扇速度控制以及冗餘鈦金級電源供應器(PSU)確保最佳的散熱效果和能源效率。亦有液冷方案供選擇。
AMD Instinct™ 解決方案應用

AI 推論
高記憶體頻寬、大容量記憶體加上對低精度運算(INT8/INT4)的支援,使 Instinct 平台非常適合 AI 推論工作負載。這些特性能有效處理大型資料集與高吞吐量批次處理,對即時及大規模推論應用至關重要。

生成式 AI
生成式 AI 需要快速處理大型模型、高吞吐量,以及對長上下文視窗(context window)的支援。Instinct MI350 GPU 提供高頻寬記憶體與大規模平行運算能力,實現高效的訓練與推論、更快速的 token 生成,以及可擴展的高品質內容創作。

代理式 AI
代理式 AI 需要持續推理、快速決策,以及跨多個模型的協調能力。Instinct MI350 GPU 提供高容量記憶體、快速互連與大規模平行運算能力,支援低延遲執行,並有效擴展複雜的多步驟代理工作流程。

高效能運算
HPC 應用中的複雜問題求解通常涉及模擬、建模與資料分析,以獲得更深層的洞察。GPU 提供所需的平行運算能力,同時仍需依賴 CPU 進行數學運算中的序列處理,以達到最佳效能。
精選最新產品