Overview for the PCIe Card or Module
PCIe CEMOAM

| Feature | MI350P |
|---|---|
| Form Factor | Dual-slot PCIe CEM |
| GPU Architecture | AMD CDNA™ 4 |
| GPU Compute Units | 128 |
| INT8 / INT8 (Sparsity) | Supported (w/ sparsity 2:4) |
| FP8 | Supported (w/ sparsity 2:4) |
| FP16, BF16 | Supported (w/ sparsity 2:4) |
| MXFP4 | Supported |
| FP64 | Supported |
| Dedicated Memory Size | 144 GB HBM3E |
| Memory Bandwidth | 4.0 TB/s |
| Bus Interface | PCIe Gen5 x16 |
| Cooling | Passive |
| Power Connector | 16-pin 12VHPWR |
| TBP | 600W (450W configurable) |
| Virtualization Support | Up to 4 partitions |

AMD Instinct™ MI300 Series
OverviewSpecifications

Accelerators for the Exascale Era
- Designed for the most demanding workloads, the AMD Instinct MI325X GPU delivers 256GB of memory and 6 TB/s bandwidth, combining exceptional performance with enhanced power efficiency and support for matrix sparsity to optimize AI training and inference.
- The world's first unified data center APU, AMD Instinct MI300A, breaks through performance bottlenecks between CPU and GPU, eliminating programming overhead and simplifying data management.
- Powered by AMD EPYC™ processors and AMD Instinct™ GPUs and APUs, the world’s fastest supercomputers, El Capitan and Frontier, demonstrate outstanding performance and energy efficiency on both the TOP500 and GREEN500 lists, proving AMD's leadership in HPC and AI acceleration.
GIGABYTE delivers advanced servers built for the Exascale era, featuring the AMD Instinct™ MI325X and MI300X GPUs as Open Accelerator Modules (OAMs) on a universal baseboard (UBB) inside GIGABYTE G-series servers. The AMD Instinct™ MI300A APU, which integrates CPU and GPU into a single package, is available in the GIGABYTE G383 series with a four-LGA-socket configuration. Together, these systems provide exceptional compute density, scalability, and cooling efficiency, empowering enterprises and research institutions to drive innovation in AI and HPC with confidence.
Optimize Next Gen Innovation with AMD ROCm™ 7.0
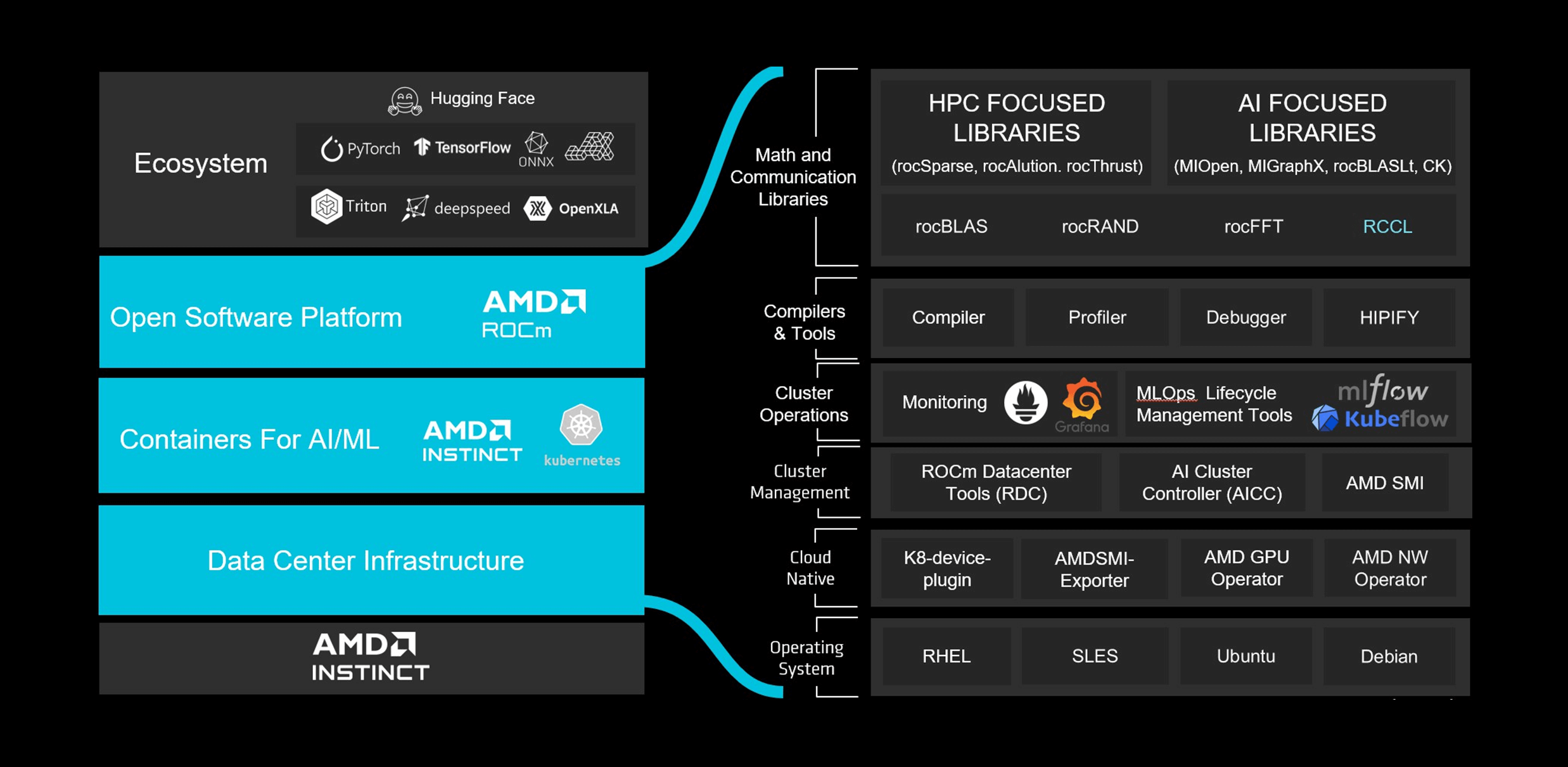
The AMD ROCm™ 7.0 software stack is a key differentiator that enables high-performance AI and HPC development with minimal code changes. AMD Instinct™ MI350 Series GPUs are fully optimized for leading frameworks such as PyTorch, TensorFlow, JAX, ONNX Runtime, Triton, and vLLM, and offer Day 0 support for popular models through automatic kernel generation and continuous validation.
|
|
[1] (MI300-080): Testing by AMD as of May 15, 2025, measuring the inference performance in tokens per second (TPS) of AMD ROCm 6.x software, vLLM 0.3.3 vs. AMD ROCm 7.0 preview version SW, vLLM 0.8.5 on a system with (8) AMD Instinct MI300X GPUs running Llama 3.1-70B (TP2), Qwen 72B (TP2), and Deepseek-R1 (FP16) models with batch sizes of 1-256 and sequence lengths of 128-204. Stated performance uplift is expressed as the average TPS over the (3) LLMs tested. Results may vary.
Select GIGABYTE for the AMD Instinct™ Platform

Compute Dense
Servers built compute dense: UBB GPUs supported in air-cooled 8U and liquid-cooled 4U servers, and PCIe CEM supported in 2U and 4U servers.

High Performance
Custom server design ensures stable, peak performance from top-tier CPUs and GPUs, to deliver the highest possible results.

Scale-out
Servers have multiple expansion slots to be populated with Ethernet or InfiniBand NICs for high-speed communication between connected nodes.

Advanced Cooling
With the availability of server models using direct liquid cooling (DLC), CPUs and GPUs can dissipate heat faster and more efficiently with liquid cooling than with air.

Energy Efficiency
Real-time power management, automatic fan speed control, redundant Titanium PSUs, and the DLC option ensure optimal cooling and power efficiency.
Applications for AMD Instinct™ Solutions

AI Inference
High memory capacity and bandwidth, along with support for lower precision (INT8 / INT4) make Instinct platforms well-suited for AI inference. These features enable efficient handling of large datasets and high-throughput batch processing, which are critical for real-time and large-scale inference applications.

Generative AI
Generative AI requires fast processing of large models, high throughput, and support for long context windows. Instinct MI350 GPUs deliver high-bandwidth memory and massive parallel compute, enabling efficient training and inference, faster token generation, and scalable, high-quality content creation.

Agentic AI
Agentic AI requires continuous reasoning, rapid decision-making, and coordination across multiple models. Instinct MI350 GPUs provide high memory capacity, fast interconnects, and massive parallel compute, enabling low-latency execution and efficient scaling of complex, multi-step agent workflows.

HPC
Complex problem solving in HPC applications involves simulations, modeling, and data analysis to achieve greater insights. Parallel processing from the GPU is needed, but also there is heavy reliance on the CPU for sequential processing in mathematical computations.
Featured New Products








Resources




Topic
GIGABYTE AI Solutions for Every AI Application