
















Advanced
Single & Multi Core Performance of an Erasure Coding Workload on AMD EPYC
Examining what erasure coding throughput can be achieved with an AMD EPYC 7601 processor teamed up with the MemoScale Erasure Coding Library. The tests have been performed with a GIGABYTE MZ31-AR0 server motherboard.
INTRODUCTION
TRENDS - INCREASING DATA GROWTH AND FASTER STORAGE DEVICES
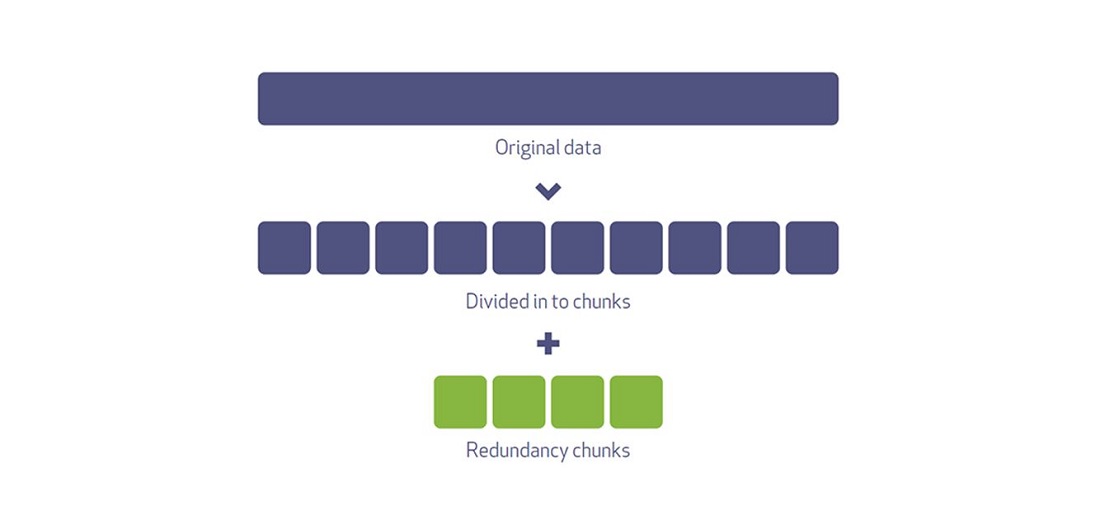
THE ROLE OF ERASURE CODING IN DATA STORAGE
AMD EPYC
GIGABYTE SERVER MOTHERBOARDS
MEMOSCALE ERASURE CODING LIBRARY
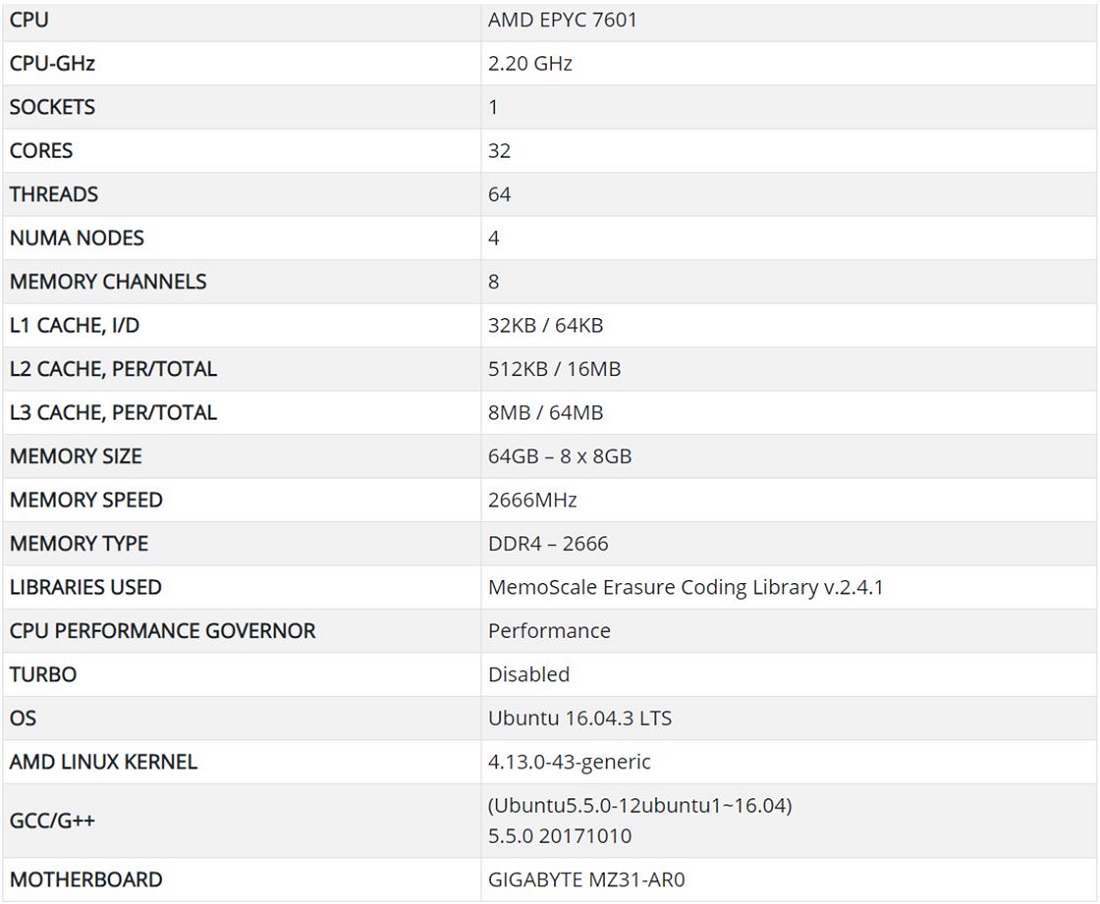
SYSTEM CONFIGURATION
HOW WE TESTED
ENCODING AND DECODING DATA WITH ERASURE CODING
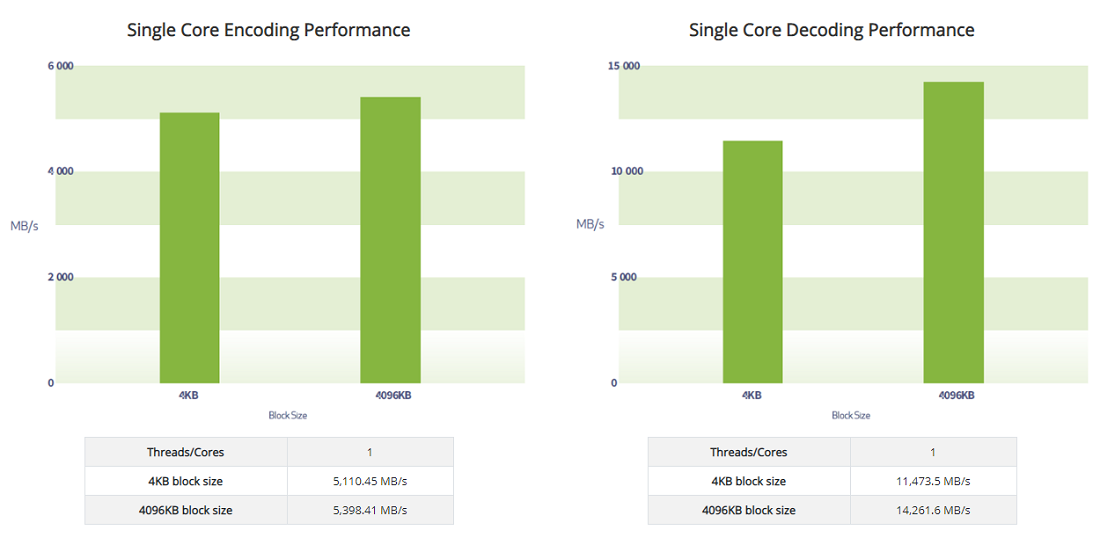
SINGLE CORE ENCODING & DECODING PERFORMANCE
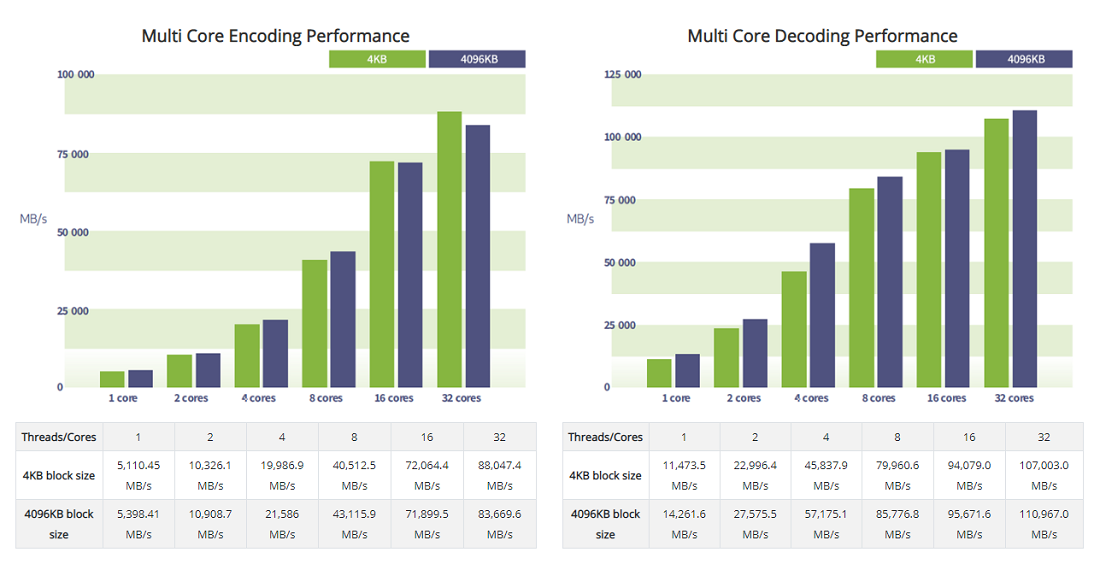
MULTI CORE ENCODING & DECODING PERFORMANCE
CONCLUSION

AMD EPYC
Server
PCIe
WE RECOMMEND


RELATED ARTICLES

Tech Guide
How to Pick the Right Server for AI? Part Two: Memory, Storage, and More
The proliferation of tools and services empowered by artificial intelligence has made the procurement of “AI servers” a priority for organizations big and small. In Part Two of GIGABYTE Technology’s Tech Guide on choosing an AI server, we look at six other vital components besides the CPU and GPU that can transform your server into a supercomputing powerhouse.

Success Case
The European Organization for Nuclear Research Delves into Particle Physics with GIGABYTE Servers
The European Organization for Nuclear Research (CERN) bought GIGABYTE's high-density GPU Servers outfitted with 2nd Gen AMD EPYC™ processors. Their purpose: to crunch the massive amount of data produced by subatomic particle experiments conducted with the Large Hadron Collider (LHC). The impressive processing power of the GPU Servers’ multi-core design has propelled the study of high energy physics to new heights.

Success Case
GIGABYTE’s GPU Servers Help Improve Oil & Gas Exploration Efficiency
GPU-accelerated servers are used in industries such as oil and gas exploration to deliver powerful computing capabilities, helping to quickly and accurately analyze large and complex data sets to reduce exploration costs. GIGABYTE uses industry-leading HPC technologies to provide customers in the oil and gas industry with GPU-accelerated servers that deliver top-tier computing performance.

Component
GRAID: A Data Protection Solution for NVMe SSDs
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates